
So you’ve written a nice new Heroku app and have tested it thoroughly – it seems really fast – yay!!! And what do I mean by thoroughly… so you tried out all the functionality, everything works as you’ve expected, and the response time seems A-ok!
Well at least it seems ok when there’s one request at a time…. but you wonder what happens when you go live and the floodgates open… what is the response time going to be like then and how will you know what your users are experiencing?
Thanks for Sweet Logging
Heroku logs provide you with the information you require to understand your application latency. In other words whether you are running a single user test, testing under load, or are running a live system, you can fully understand what your users are experiencing. BTW check out Blazemeter for load testing in the cloud if you are planning on doing any load tests. It solves that age old problem of looking for more machines to push up your user load by harnessing the infinite and instant resources of the cloud.
When a request completes in Heroku you get a HTTP 200 response in the logs, which tells you that everything was ok, and that the request returned successfully. This includes information on how long the request took:
62 <13>1 2012-07-13T06:33:24+00:00 app web.8 – – Completed 200 OK in 117ms (Views: 0.2ms | ActiveRecord: 1.8ms | Solr: 0.0ms)
Furthermore if a request takes more than 30 seconds to complete or if there is a problem with the request completing, Heroku will produce error codes in the logs to notify you of this. Two of the error codes worth looking out for are:
- H12 Request time out: An HTTP request took longer than 30 seconds to complete.
- H11 Backlog too deep: There are too many HTTP requests in your backlog. Note, the backlog is the number of requests waiting to be processed. If you’re using the default (one dyno), your application can only process one request at a time. This is usually sufficient for a few simultaneous requests, however as your user load increases, requests will get queued. If this queue continues to grow there comes a point when Heroku starts to turn away requests. Any refused requests will get the H11 (Backlog too deep) error message.
Heroku actually provide some good guides on how to go about resolving both the H11 and H12 errors above. Check out their tips for resolving request time outs as well their backlog too deep article.
Essentially, if you are getting request time outs you will need to look at optimizing your code such that request times are reduced. For a decent user experience request times should really not exceed 500ms so if you are getting request time outs (>30s) you are way off!
For the backlog too deep issue you have two options, you can improve the response time of an individual request to squeeze more requests onto a given dyno or you can buy more dynos to handle the load. Obviously there is only so much you can optimize so as load increases you will need to buy dynos at some stage.
Heroku Log Intelligence
So it’s perfectly reasonable to use ‘tail -f’ when running single user tests, and it will be fairly easy to scan your log events for your request response times. If you are doing any sort of load testing, however, or are interesting in viewing your logs once your system goes live you will need to use a log management service so that you can process your logs in some sort of efficient way.
Naturally I’d recommend Logentries for this:
- because I’m biased 😛 and
- because Logentries is the only Log Management Solution that comes with preconfigured Heroku Log Intelligence.
With Heroku Log Intelligence you will get sent email notifications when any H11 or H12 errors occur in your logs – so if your apps are starting to become slow, or worse still, requests are getting dropped, you will get notified about it immediately. Furthermore when you view your logs via the Logentries UI, any log events containing Heroku error codes will be automatically tagged so you can immediately see when and how often they have occurred (even if you are out of the office and on the move).
Heroku error codes are a good way to know when your application is in trouble, but if you want to keep a more fine grained eye on response times it may make sense to create your own alerts and tags. Logentries allows you to make use of regular expressions for alerting – so you can easily generate an alert when, for example, response times are above 1000ms.
Real World Example
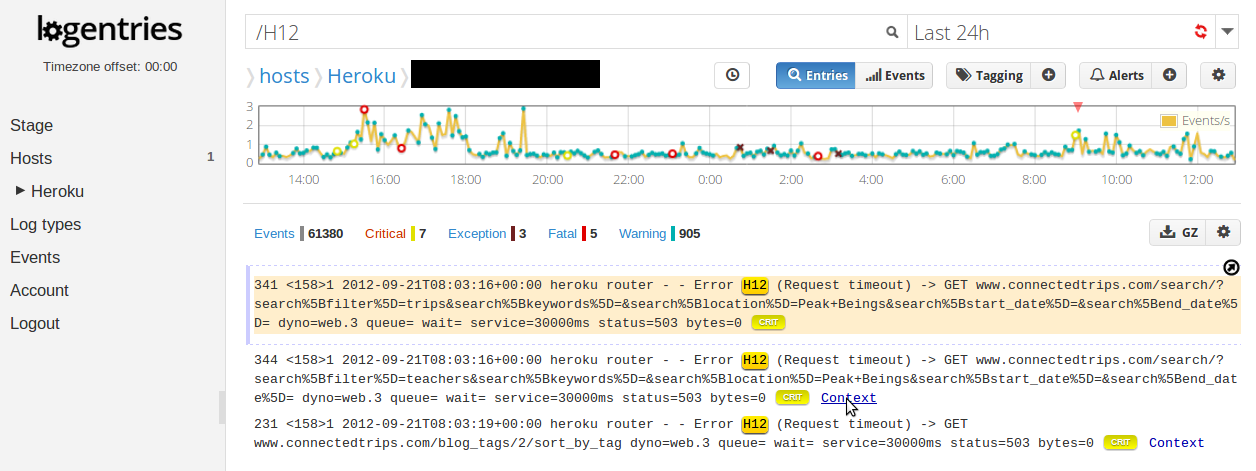
The Logentries graph below shows how effective this kind of alerting can be. It shows 61,380 log events over a 24hr period from a live production Heroku application (note some sensitive data has been removed from the image). Searching for the string ‘H12’ shows that there were in fact 3 individual H12 errors that occurred during this time which meant 3 requests took more than 30 seconds to complete. That’s 3 requests out of thousands, which is probably not the end of the world for your application, but you would still like to know why this is happening. Luckily, Logentries will notify you when these H12 errors occur so you will know about these right away. Logentries will also highlight these (in this case with the ‘Critical’ tag) so you can see them highlighted when you log in.
Clicking on the ‘context’ link after each search result below in fact uncovered the culprit – which as it turned out was a result of geo-location lookup for invalid addresses (fixed now thank you!). Clicking the context link will unveil the events that occurred immediately before and after a given search result, so you can search for an issue in your logs and then see what happened right before and after it.
So how do you know if your Heroku app is slow??? Because Logentries just told you so!!!!
