
We’ve had a lot of people asking for the Log Management Primer for a while now. And, surprisingly, many of these folks have a strong technical background, including developers. Some want it for themselves, and some want it to pass on to a colleague, manager, etc. I’m going to explain what logs are, where they come from and how you can get your logs.
If you’re a developer, this post probably isn’t for you as we don’t dig into the code level nitty gritty, but it will give you a high level overview of logs, where they come from and how they get sent to a third party service.
Where Do Logs Come From?
Logs are machine data generated by any sort of application or the infrastructure used to run that application. They created a record of all the events that happen in an application system. They are also usually unstructured or semi-structured and often contain common parameters such as a time stamp, IP address, process id, etc…
Logs can come from throughout the application stack, including:
- Mobile Apps/Devices
- Client Browser
- Web Application code
- Platform as a Service - Application server
- Database
- Router
- Infrastructure as a Service - Operating System
- Other Services (think AWS S3, RDS etc…)
- On Premise - Virtual Machines
- Hypervisor
- Network
- Hardware - Server
- Etc…
[
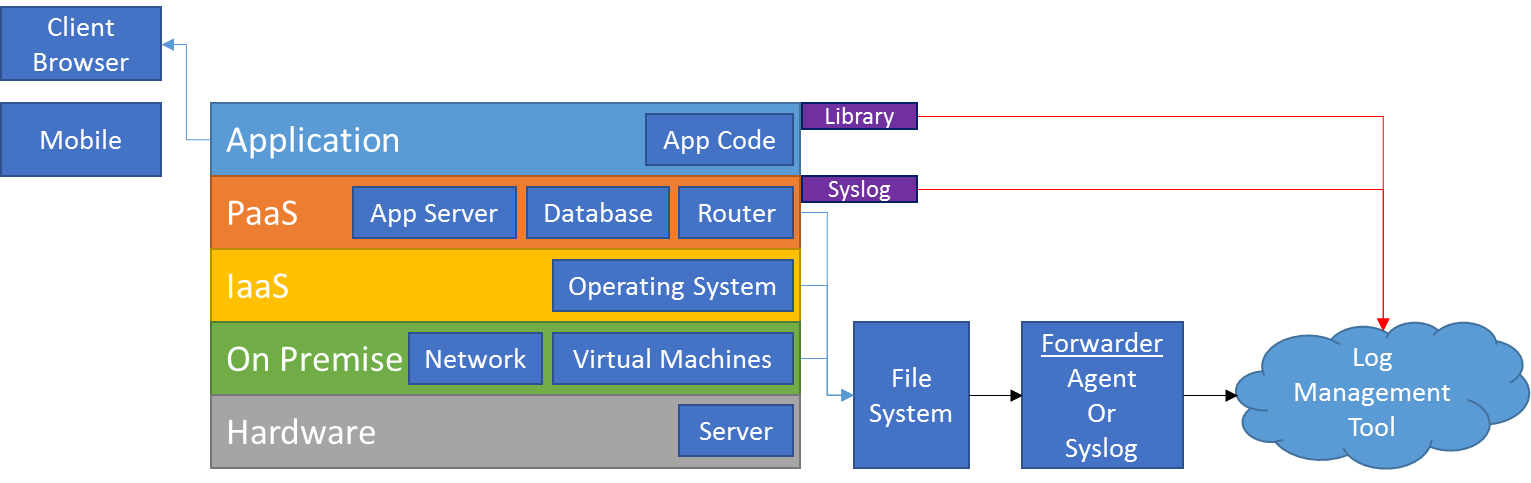
How to Get Your Logs
Pretty much all levels of the application stack kick out log data. Different levels, though, lend themselves to different methods of gaining access. That said, there are some similarities across the levels, though.
File System
For the most part, logs are sent to a file system by default. Without further action, that’s where they’d meet an untimely demise as they’re deleted to make way for new logs. The file system is not and ideal place for long term storage for this data and often only a relatively small amount of data is stored here regularly as logs often get rotated after they reach a certain size. If you want to store more of your log data, or if you want to perform any analysis, graphing, alerting, tagging, etc., then you’ll need more than just the file system. Often people will archive logs periodically (e.g. to S3) or will send them to a third party service.
Everything from the application down through the hardware level can send logs to the file system…it’s just a matter of how. For example, your applications, the app server, database, OS, and VMs will all normally send data straight to a file system.
So, now that you’ve got your logs flying to the file system, what do you do to get them out of there and into somewhere with a bit more longevity? When sending them on to a third party logging tool there are two main ways to do this, via syslog or a collector agent.
Syslog
Syslog is the protocol you’ll use, most likely, if you’re running a Linux setup. If you’re not running Linux, move on; Syslog is the domain of Linus Torvalds and those who use his creation.
Once you’ve sent logs to the file system, Syslog will step in and forward these to your log analysis tool. Note – you’ll need to configure syslog accordingly. Or, in some cases, you can use it to forward directly from the PaaS layer (e.g. logplex from Heroku supports this).
There are several flavors of Syslog,:
The benefits of Syslog are:
- Its available out of the box on all Linux distros
- It’s secure - You can send logs via TCP (secure) or UDP (unsecure)
- It’s a known, standard protocol that is widely supported (for instance, see our documentation on Syslog)
The downfalls? It can be challenging to configure if you don’t know what you are doing. Although if you are following a good set of docs it should take no longer than a few minutes. Also older flavors of Linux can have limitations e.g. with syslogd you cannot send data from non-syslog log files that may exist elsewhere on your file system outside of the /var/logs folder where all your syslog logs live. Rsyslog solves this however and ships with most distros these days. Finally, although Snare is a windows equivalent syslog, this approach is largely only used on Linux systems.
Agent
An agent is a lightweight application that runs on your server and (in this case) forwards your logs from the file system to your log management tool. Agents are great for when you’re not just pulling logs out of your Linux box (where you may just use Syslog). That said, you can still use them on Linux if you’re so inclined. They’ll usually send logs to your cloud log solution via an API
The benefits of agents (or at least the Logentries agent):
- Quick
- Easy to set up
- Secure (they use TCP)
- You can modify the source to filter sensitive data from being logged
The downsides are:
- It must be updated appropriately – although the Logentries agent is plugged into the relevant Linux package management systems – so this is taken care of in this instance
- Also sometimes people are reluctant to run unknown pieces of code on their systems – we’ve open sourced our agent for this reason – so you can look at exactly what is running on your machine. That being said you may not have the time or the inclination to do this and may prefer to use a more tried and tested approach like syslog.
- Scaling issues in relation to deploying agents can also arise – e.g. when you’re trying to deploy on ~100 servers …do you want to do that manually? Luckily, there are tools like Puppet or Chef to automate this.
Libraries
Libraries can be set up to send logs to a logging service from the application layer via an API. Each library supports a specific language (e.g. java, ruby, node.js, c#, python, etc…). The benefit of libraries is that you can still get your logs, even if you only have access at the application code level. Many PaaS providers do not provide file system access or a way to forward logs to a third party service – so libraries are a must in this case.
Client side libraries also allow you to get a view into what is happening from an end user’s perspective. For example, they can allow you to log from your end user’s browser so that you can get a full end to end view of your system. You can use our le.js library to do just that!
Libraries can also be used to log from your mobile apps – check out our android library for this.
Conclusion
So there you have it, now you know how where logs come from and how your logs get from the different parts of your application stack to your log analyzer – all logs from the browser, to the backend, to the log management solution of your choice.
