
Hello, fellow AWS enthusiasts! Today, let’s talk about AWS S3 buckets and how InsightIDR can help you monitor important activity. You might be wondering, “How can we get this level of granularity, and from there, what do we do with this visibility?” Let’s answer these questions by walking through this journey step-by-step.
First of all, I will help answer the question of why this is important. Some of you out there who have been operating in these cloud-hosted environments for a while may see this as obvious, but for those just entering the space or getting familiar with it, this will serve as helpful context.
What is Simple Storage Service (S3)?
AWS started out by providing a cloud storage service called Simple Storage Service (S3). This allows users to store large amounts of data without dealing with high costs. From here, they expanded those services to include software-as-a-service (SaaS), platform-as-a-service (PaaS), infrastructure-as-a-service (IaaS), and much, much more.
Today, AWS is a leader in the space and a popular option for organizations both small and large, allowing end users the opportunity to move off traditional on-premises architecture and take advantage of cloud-hosted architecture managed by AWS. This, of course, changed the dynamics of traditional security, and we must use ways to .
Does InsightIDR have AWS integrations?
With InsightIDR, there are native integrations with AWS services such as CloudTrail and GuardDuty, along with out-of-the-box alerts that identify suspicious authentications, anomalous compute usage, new services, and more. CloudTrail, a service that tracks API audit activity across your account, is a fantastic way to gain visibility. It’s also a best practice to always have this on. CloudTrail is the key data source that can collect important S3 activity, such as when files are accessed, deleted, modified, or written to.
Why track this stuff?
So, let’s dig briefly into the why. A quick Google search for strings like “exposed data on S3,” “AWS breach,” or “AWS credential theft” will will yield many results of well-known organizations being affected. Once an attacker gains initial access, their next step is to scrape the S3 buckets for sensitive information. Often, misconfigurations expose these buckets to the world, making them inadvertently accessible for malicious actors.
As a general best practice:
- Make sure your S3 buckets aren’t public
- Use bucket policies and restrict who has access. See AWS best practices
- Take a bit of time to understand AWS bucket policies
The insider threat challenge
Assuming you have good hygiene, enabled CloudTrail, removed configuration issues with Security Groups, and so on, you still may have possible insider threats to deal with—especially when it comes to personally identifiable information (PII) and sensitive financial information such as cardholder data.
So, how can InsightIDR help?
Leveraging AWS's CloudTrail service, we can enable object-level API auditing for individual S3 buckets, which will then pipe this data into CloudTrail (which already collects API audit activity of the AWS environment). As InsightIDR natively supports CloudTrail logs, you can also collect critical object-access data from S3 storage locations all within the same stream. From there, it’s easy to create custom rules to alert when an object has been accessed, modified, or removed inside this bucket. This is in essence file integrity monitoring (FIM) / creating a HoneyFile for the S3 bucket. To set up S3 auditing, CloudTrail must already be enabled and logging data, and that should be feeding as an event source setup in InsightIDR collecting CloudTrail logs.
Related blog: Securing Your AWS Cloud Environment with InsightIDR
Configuring object-level auditing in AWS
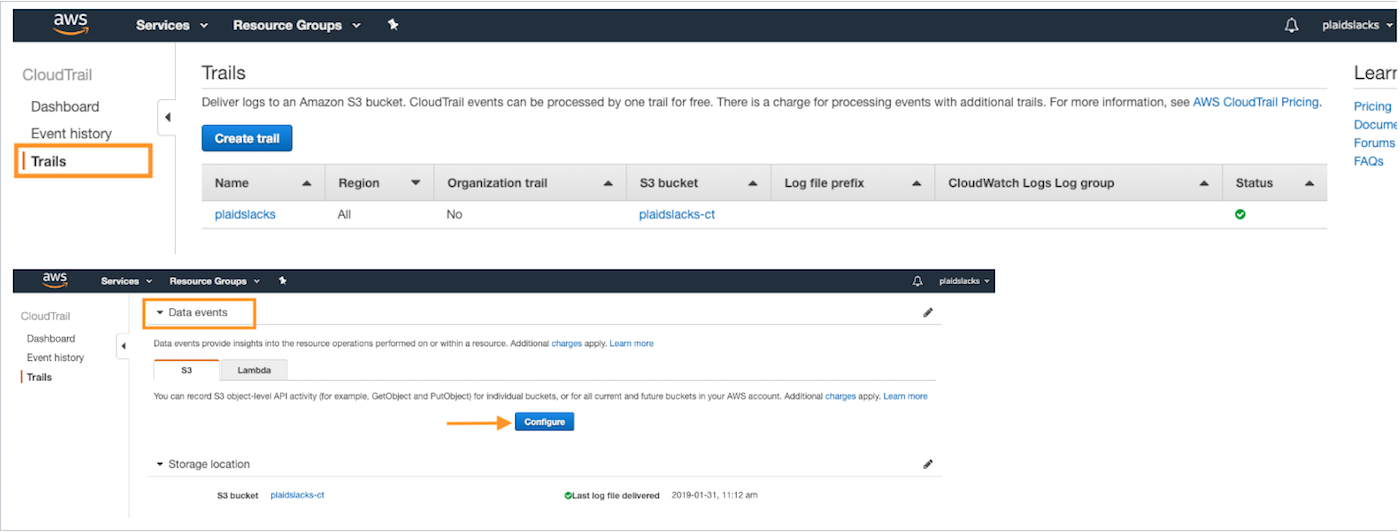
In the AWS console, navigate to Services→ CloudTrail and choose Trails. It will list the trails that have been configured. I've named this example plaidslacks, and the S3 bucket I created to collect the CloudTrail events is called plaidslacks-ct. Choose the Trail, then scroll down to the Data events section of the page and choose Configure.
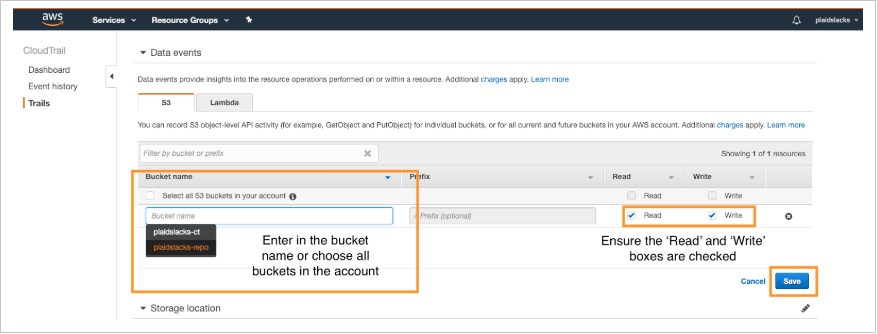
Under the Bucket name column, you can either choose all buckets in the account, or a specific one. In this example, I have created bucket plaidslack-repo to monitor object access. Make sure that both the read and write boxes are ticked, then click save.
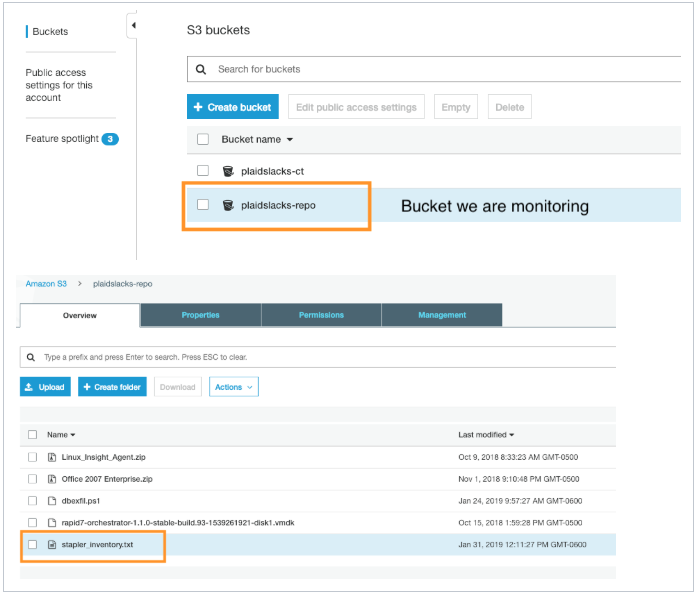
Now, we can navigate to the S3 bucket and upload a file to test. In this example, I created a txt file called stapler_inventory.txt to upload and access in our S3 bucket.
Within InsightIDR, we can verify that we are now seeing the object-access events in LogSearch. Note, these events will be under the unparsed LogSet in LogSearch. We will be specifically looking for 'GetObject' events from AWS indicating that the object has been accessed. Below is an example query I used to pull these specific events:


Now that we have object-access logs from our S3 bucket coming into InsightIDR, we can create a custom Honey File alert for when any objects are accessed from inside the bucket. Using the example query above, we can use this as the pattern entry for the new rule creation.
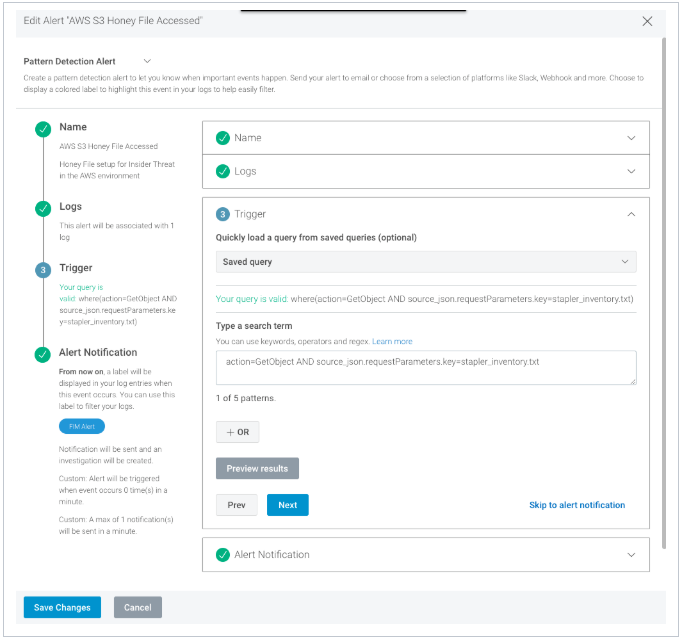
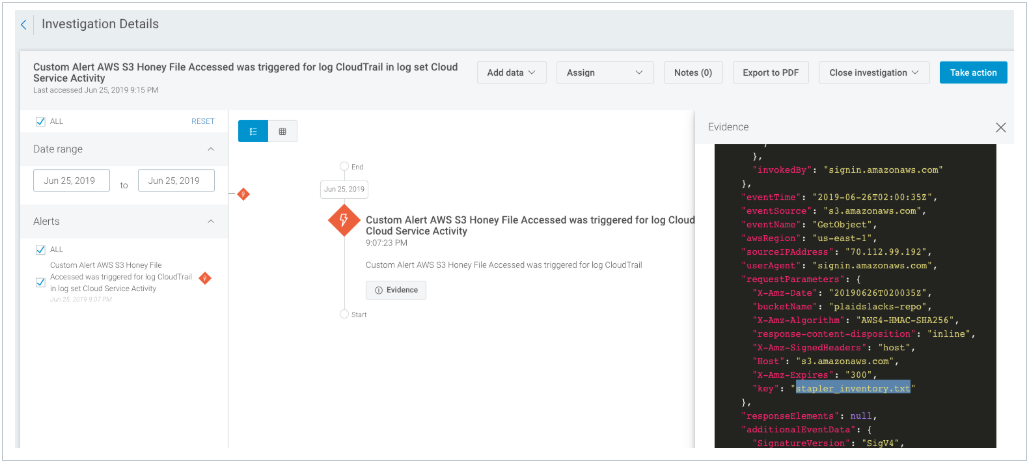
After accessing the object, i.e., stapler_inventory.txt, a few moments later, we should see our custom Honey File alert triggered, revealing that someone had accessed this file in S3.
As an added bonus, we can create an AWS Activity Dashboard to track S3 activity! The dashboard will reveal what S3 buckets are active (in frequent use), files being accessed in the bucket by file name, document names that contain “password” in them, honey-file access activity, and more.
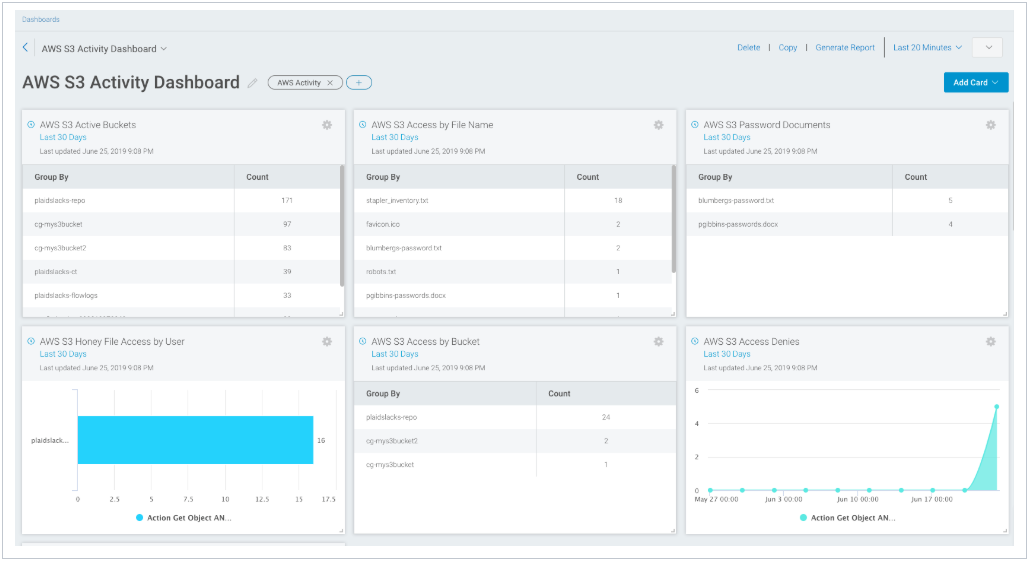
Queries that power the above AWS Activity Dashboard
| Dashboard Description | Dashboard Query |
|---|---|
| AWS S3 Active Buckets | groupby(source_json.requestParameters.bucketName) calculate(count) |
| AWS S3 Access by File Name | where(action=GetObject)groupby(source_json.requestParameters.key) calculate(count) |
| AWS S3 Password Documents | where(source_json.requestParameters.key=/.password..(doc |
| AWS S3 Honey File by User | where(action=GetObject AND source_json.requestParameters.key=stapler_inventory.txt)groupby(source_json.userIdentity.userName) calculate(count) |
| AWS S3 Access by Bucket | where(action=GetObject)groupby(source_json.requestParameters.bucketName) calculate(count) |
| AWS S3 Access Denies | where(action=GetObject AND source_json.errorCode="AccessDenied") calculate(count) |
And that’s it! If you’ve found this helpful, or have built your own use cases, let us know in the comments. If you’d like to learn more about how InsightIDR can monitor your hybrid, modern environment, check out our blog series around Microsoft Azure and AWS, or start a trial today.
