
I have logs on my mind right now, because every spring, as trees that didn’t survive the winter are chopped down, my neighbor has truckloads of them delivered to his house. All the logs are eventually burned up in his sugar house and used to make maple syrup, and it reminds me that I have some logs I’d like to burn to the ground, as well!
If you’re reading this blog, chances are you probably have some of these ugly logs that are messy, unstructured, and consequently, difficult to parse. Rather than destroy your ugly logs, however tempting, you can instead use the Custom Parsing tool in InsightIDR to break them up into usable fields.
Specifically, I will discuss here how to use Regex Editor mode, which assumes a general understanding of regular expression.
Many logs follow a standard format and can be easily parsed with the Custom Parsing tool using the default guided mode, which is quite easy to use and requires no regular expression. You can read more about using guided mode here.
If the logs parse well with guided mode, you will likely use it to parse your logs. However, for those logs that lack good structure, common fields, or just do not parse correctly using guided mode, you may need to switch to Regex Editor mode to parse them.
Example 1: Key-Value Pair Logs Separated With Keys
Let’s start by looking at some logs in a classic format, which may not be obvious at first glance.
The first part of these logs has the fields separated by pipes (“|”). Logs that have a common field, like a pipe, colon, space, etc., separating the values are usually easy to parse and can be parsed out in guided mode.
However, the problem with these logs is that the last part contains a string that’s separated by literal strings of text rather than a set character type. For example, if you look at the “msg” field, it is an unstructured string that might contain many different characters — the end of the value is determined by the start of the next key name, “rt”.
May 26 08:25:37 SECRETSERVER CEF:0|Thycotic Software|Secret Server|10.9.000033|500|System Log|3|msg=Login Failure - ts2000.com\hfinn - AuthenticationFailed rt=May 26 2021 08:25:37 src=10.15.4.56 Raw Log/Thycotic Secret Server
May 26 08:25:37 SECRETSERVER CEF:0|Thycotic Software|Secret Server|10.9.000033|500|System Log|3|msg=Login attempt on node SECRETSERVER by user hfinn failed: Login failed. rt=May 26 2021 08:25:37 src=10.15.4.56
Let’s see how parsing these logs with the Custom Parsing Tool works. I have followed the instructions at https://docs.rapid7.com/insightidr/custom-parsing-tool/ and started parsing out my fields. Right away, you can see I’m having a problem parsing out the “msg” field in guided mode. It’s not working like I want it to!
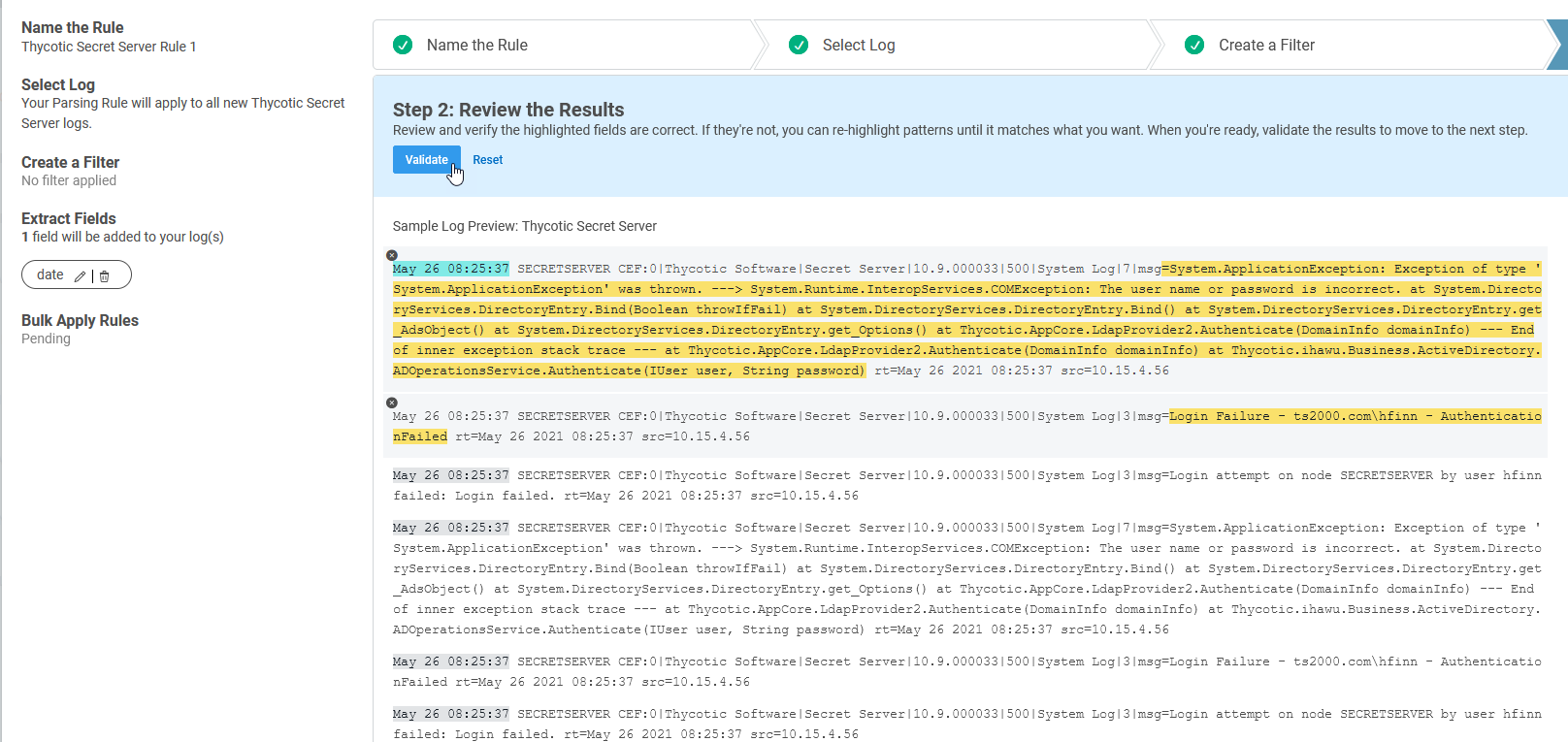
This is where it is a good idea to switch to Regex Editor mode rather than continuing in guided mode. As such, I have selected the Regex Editor, and you can see that displayed here:
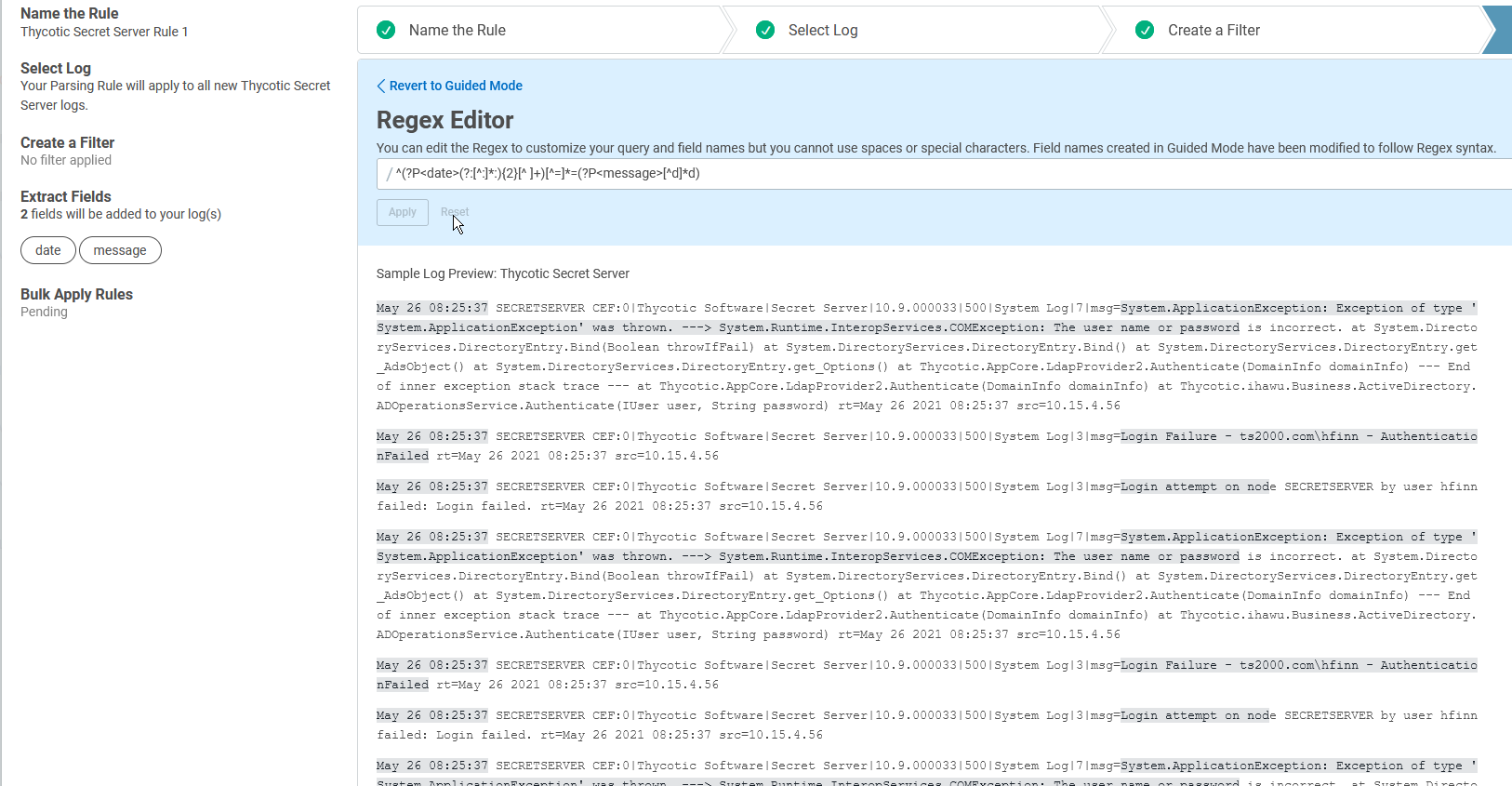
Whoa! This regex might look daunting at first, but just remember from our previous lesson that you can use an online regex cheat sheet or expression builder to make sense of any parts you find confusing or unclear.
Here is what the Regex Editor has so far, based on the two fields I added from guided mode (date and message):
^(?P<date>(?:[^:]*:){2}[^ ]+)[^=]*=(?P<message>[^d]*d)
The regular expression for the field I decided to name “message” is the part that’s not working like I want. So, I need to edit this part: (?P<message>[^d]*d).
Remember, this is a capture group, so the regular expression following the field name, “<message>”, will be used to read the logs and extract the values for each one. In other words, in Log Search, the key-value pair will be extracted out from the logs as follows:
(?P<key>regex that will extract the value)
“[^d]*d” is not working, so let’s figure out how to replace that. There are a lot of ways to go about crafting a regular expression that will extract the field. For example, one option might be to extract every character until you get to the next literal string:
^(?P<date>(?:[^:]*:){2}[^ ]+)[^=]*=(?P<message>.*)rt=
This works, but it is somewhat inefficient for parsing. It’s outside our scope here to discuss why, but in general, you should not use the dot star, “.*”, for parsing rules. It is much more efficient to define what to match rather than what to not match, so whenever possible, use a character class to define what should be matched.
Create the character class and put all possible characters that appear in the field into it:
^(?P<date>(?:[^:]*:){2}[^ ]+)[^=]*=(?P<message>[\w\s\.-\\]+)
These Thycotic logs have a lot of different characters appearing in the “msg” field, so defining a character class like I’m doing here, “[\w\s\.-\\]”, is a bit like playing pin the tail on the donkey, in that I hope I get them all!
Let’s look at another way to extract a text string when it does not have a standard format. Remember that “\d” will match any digit character. Its opposite is “\D”, which matches any non-digit character. Therefore, “[\d\D]+” matches any digit or non-digit character:
^(?P<date>(?:[^:]*:){2}[^ ]+)[^=]*=(?P<message>[\d\D]+)rt=
One thing to point out here is that, although defining the specific values in the character class was a bit futzy to extract the “msg” field, this method works very well when parsing out host and user names.
In most cases, host and user names will contain only letters, numbers, and the “-” symbol, so a character class of “[\w\d-]” works well to extract them. If the names also contain a FQDN, such as “hfinn.widgets.com”, then you also need to extract the period: “[\w\d\.-]”.
Example 2: Unstructured Logs
Let’s look at some logs that are challenging to parse due to the field structure.
Logs that do not have the same fields in every log and that do not have standard breaks to delineate the fields, while nicely human readable, are more difficult for a machine to parse.
<14>May 27 16:25:31 tkxr7san01.widgets.local MSWinEventLog 1 Microsoft-Windows-PrintService/Operational 5793 Mon May 27 16:25:31 2021 805 Microsoft-Windows-PrintService hfinn User Information tkxr7san01.widgets.local Print job diagnostics Rendering job 71. 2447840
<14>May 27 16:25:31 tkxr7san01.widgets.local MSWinEventLog 1 Microsoft-Windows-PrintService/Operational 5794 Mon May 27 16:25:31 2021 307 Microsoft-Windows-PrintService hfinn User Information tkxr7san01.widgets.local Printing a document Document 71, Print Document owned by hfinn on lpt-hfinn01 was printed on XEROX1001 through port XEROX1001. Size in bytes: 891342. Pages printed: 2. No user action is required. 2447841
Let’s take a look at how we can parse out the fields in this log using guided mode. When you are using the Custom Parsing Tool, one of the first things you need to decide is if you want to create a filter for the rule:
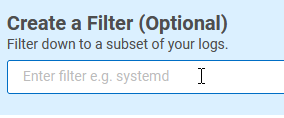
With logs, the device vendor decides what fields to create and how the logs will be structured. Some vendors create their logs so all have the same fields in every log line, no matter what the event. If your logs look like this, then you will not need to use a filter.
Other vendors define different fields depending on the type of event. In this case, you will probably need to use a filter and create a separate rule for each type of event you want to parse. Another reason to use a filter is that you just want to parse out one type of event.
Looking at my Microsoft print server logs closely, you can see that the second log has quite a few more fields than the first one: document name printed, the document owner, what printer it was printed on, size, pages printed, and if any user action is required. As such, I’m going to need to use filters and create more than one rule here.
The filter should be a literal string that is part of the logs I want to parse. In other words, how can the parsing tool know which logs to apply this rule to? Let’s start with the first type of log:
<14>May 27 16:25:31 tkxr7san01.widgets.local MSWinEventLog 1 Microsoft-Windows-PrintService/Operational 5793 Mon May 27 16:25:31 2021 805 Microsoft-Windows-PrintService hfinn User Information tkxr7san01.widgets.local Print job diagnostics Rendering job 71. 2447840
Its type is “Print job diagnostics”, so that seems like a good string to match on. I will use that for my filter.
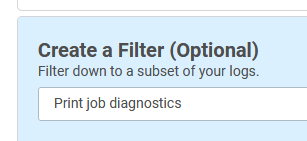
Still in the default guided mode, I’ll start extracting out the fields I want to parse. I don’t need to parse them all, just the ones I care about. As I am working my way through the log, I find that I am not able to extract the username like I want:
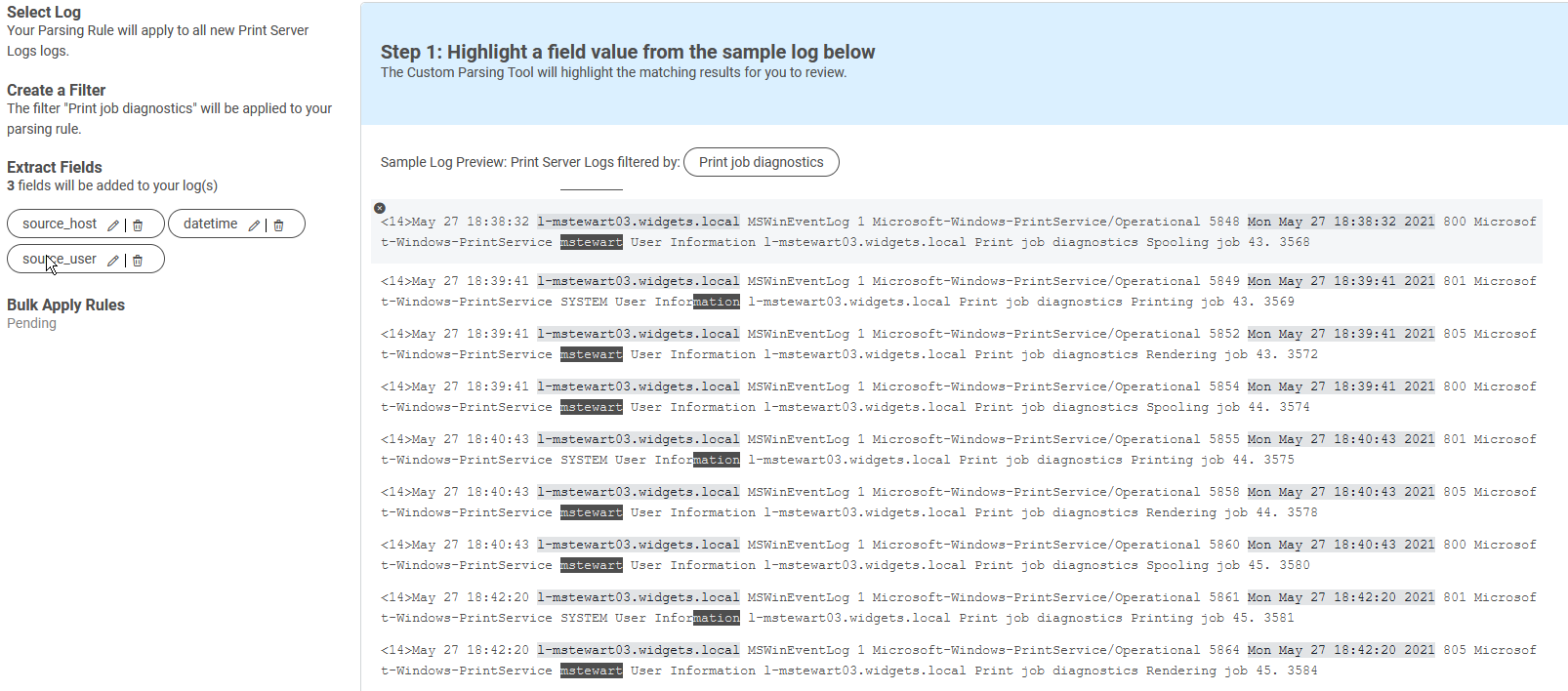
I am going to continue for the moment, however, using guided mode to define the last field I need to add.
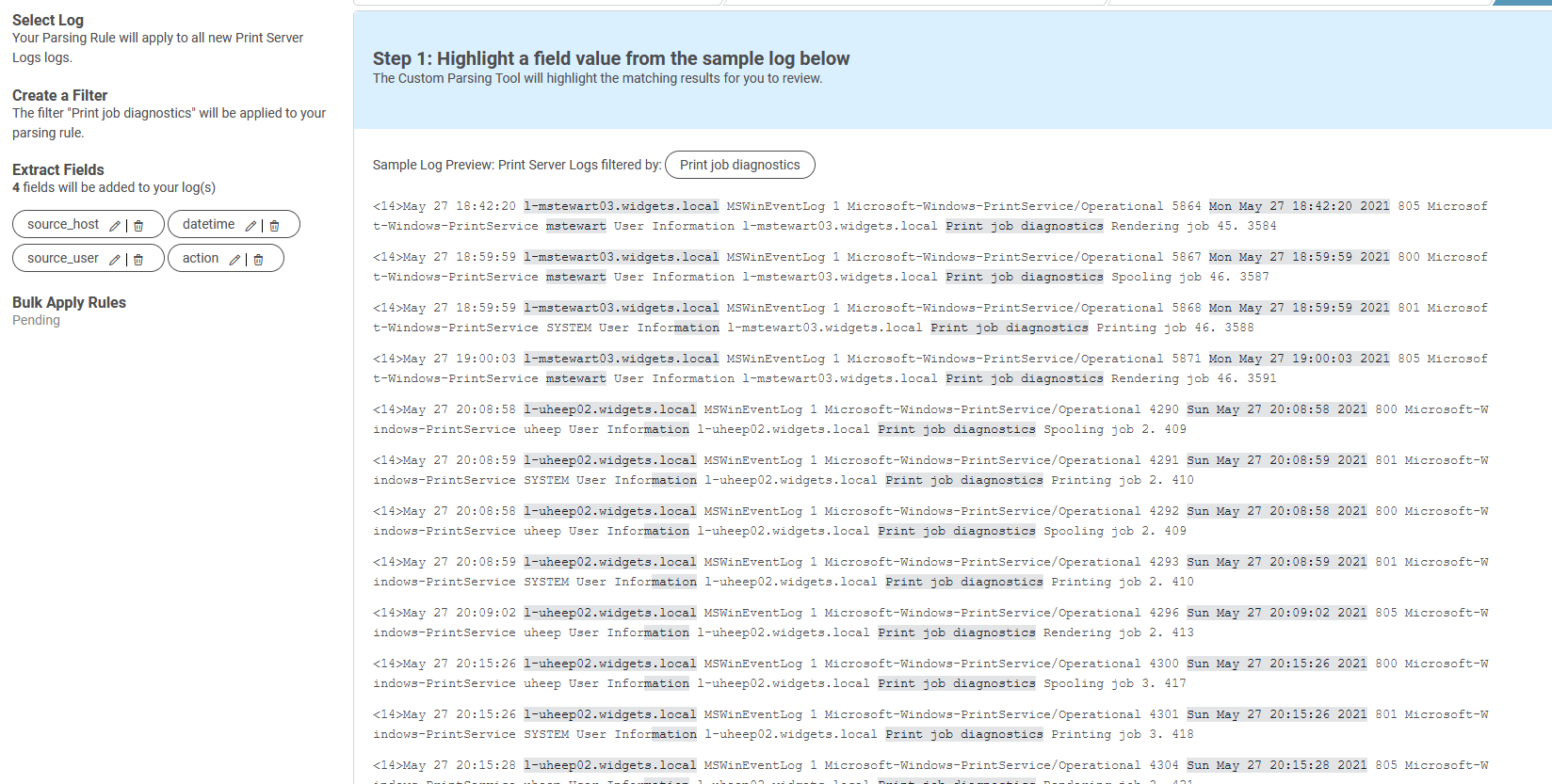
Let’s pause for a moment. I’ve created four fields. Three of them are fine, but the “source_user” field is not parsing correctly. I am going to switch now to Regex Editor mode to fix it.
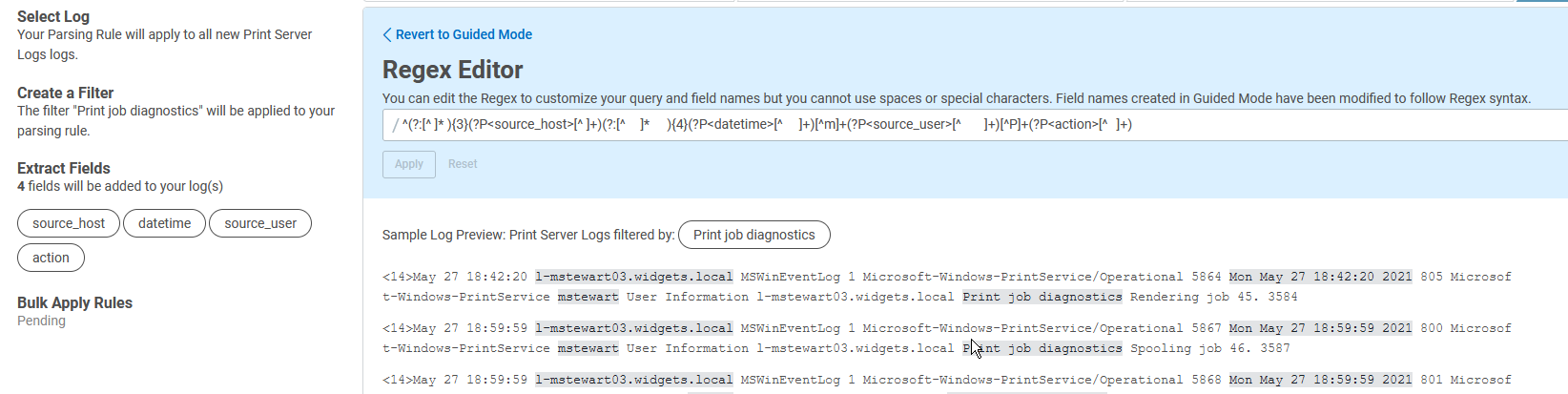
The regex created by the Custom Parsing Tool in guided mode is:
^(?:[^ ]* ){3}(?P<source_host>[^ ]+)(?:[^ ]* ){4}(?P<datetime>[^ ]+)[^m]+(?P<source_user>[^ ]+)[^P]+(?P<action>[^ ]+)
The only part I need to look at is the capture group for the field I called “source_user”:
(?P<source_user>[^ ]+)
With that said, the issue with the rule could be somewhere else in the parsing rules. However, let’s just start with the one capture group. Let’s interpret the character class first: “[^ ]”.
When the hat symbol (“^”) appears in a character class, it means “not”. The hat is followed by a space, so the character class is “not a space”. Therefore, “[^ ]+” means “read in values that are not spaces” or “read until you get to a space”.
Looking at the entire parsing rule, you can see it is counting the number of spaces to define what goes into each field. This would work out fine if spaces were the field delimiters, but that’s not how these logs work. The logs are a bit unstructured in the sense that some of the fields are defined by literal strings and others are just literal strings themselves.
Also, guided mode had a few too many beers while trying to cope with these silly logs and decided that the “source_user” field should always start with the letter “m”:
[^m]+(?P<source_user>[^ ]+)
Oops! We don’t want that! Let’s get rid of it, plus the “[^P]+”, which means to read to a literal capital P: this is how it is rolling past everything to the “Print job diagnostics”, but we can do better than that.
As humans, we know that we want the “action” field to be the literal string “Print job diagnostics”, which the Custom Parsing Tool doesn’t know. Let’s just fix these few things first. I made these changes, clicked on Apply to test them, and got an error:
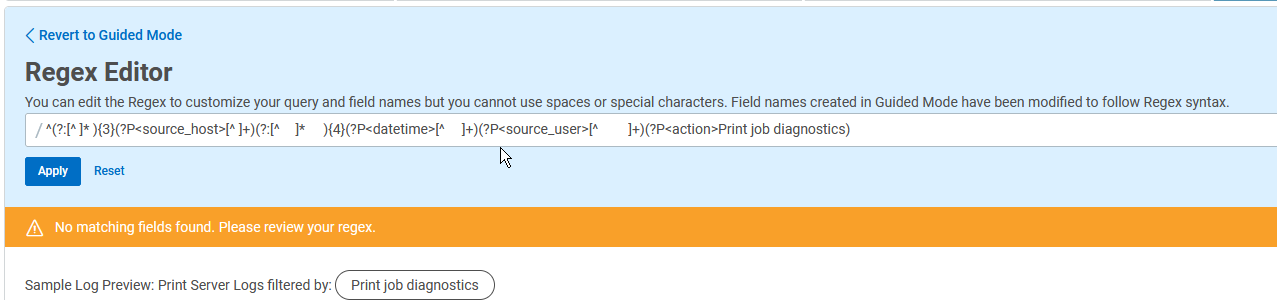
This error means I’ve goofed, and the rule does not match my logs. I know I’m on the right path, though, so I’m going to continue. The problem here is with how the regex is going from “datetime” to “source_user” and then to “action”.
Let’s stop for a moment to look at this regex:
(?:[^ ]*){3}
The “(?P<keyname>)” structure that we’ve been using is a capture group. The “(?:)” structure is a non-capture group. It means that regex should read this but not actually capture it or do anything with it. It’s also how we are going to skip past the fields we don’t want to parse. The “{3}” means “three times”. Of course, we have already seen that “[^ ]*” means “not a space” or “read until you get to a space”. So, the whole non-capture group “(?:[^ ]*){3}“ means “read everything to the next space, three times” or “skip past everything that is in the log until you have read past three spaces”.
Now, let’s look at an actual log:

The last field we read in was “datetime”, and then, we need to skip over to the “source_user” field. Let’s try to do that by skipping past the three spaces until we get there.
Next, from the “source_user” to the last field, “action”, there are four spaces. Here is my regex:
^(?:[^ ]* ){3}(?P<source_host>[^ ]+)(?:[^ ]* ){4}(?P<datetime>[^ ]+)(?:[^ ]* ){3}(?P<source_user>[^ ]+)(?:[^ ]* ){4}(?P<action>Print job diagnostics)
I have added “(?:[^ ]* ){3}“ to skip past 3 spaces and done the same thing later to skip past 4 spaces, using a “{4}” to denote 4 spaces. Let’s see if it works:
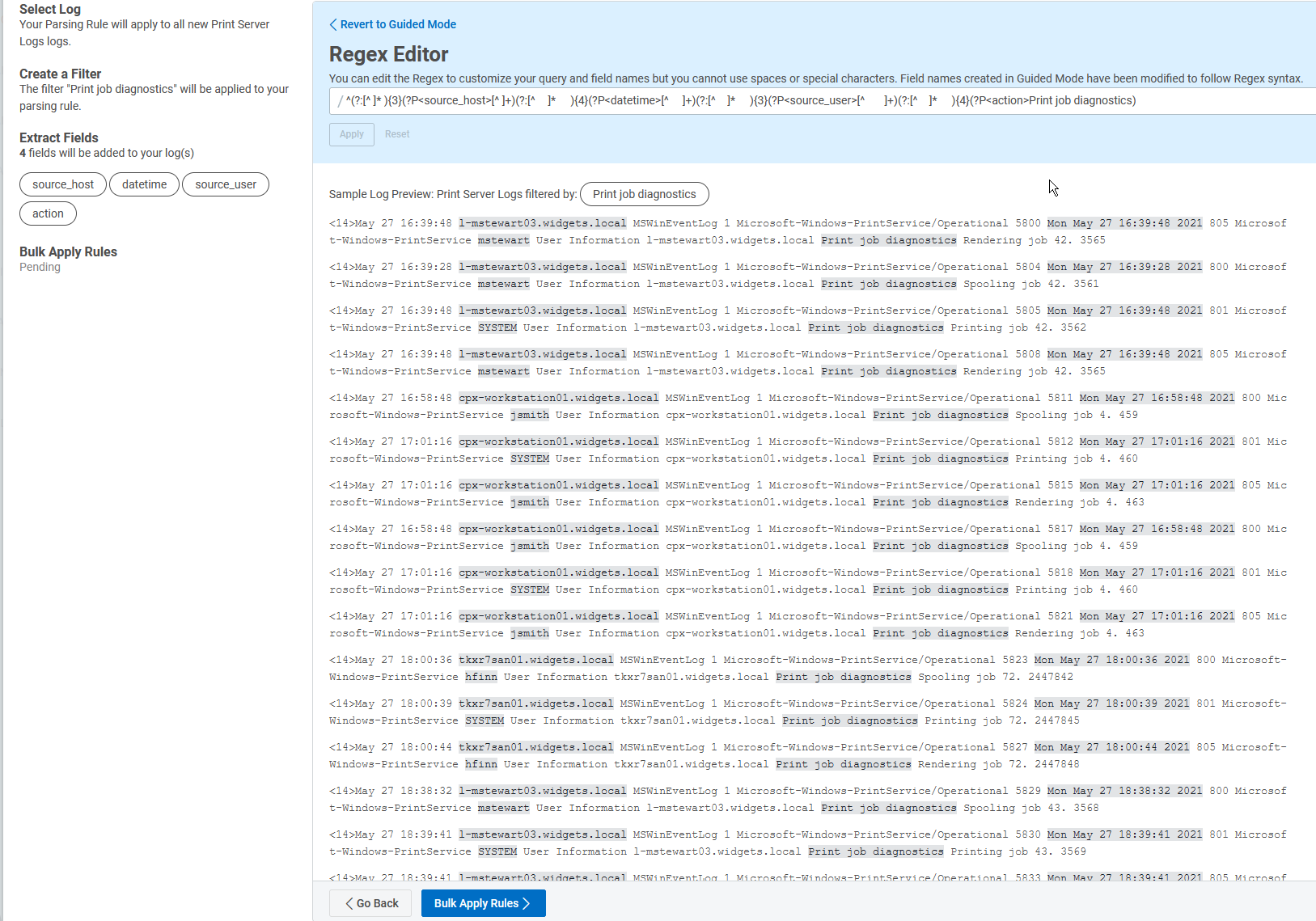
The tool seems to be happy with this, as all the fields appear correctly, so I will go ahead with applying and saving this rule.
If you are at this spot with your logs except the tool is not happy and you are getting an error, I have a couple of tips for you to try:
- Sometimes, the tool works better if you do parse every field, even if you do not particularly care about them. Try parsing every field to see if that works better for you.
- Occasionally, it is easier to just parse out one (or maybe two or three) fields per rule. This is especially true if the logs are very messy and the fields have little structure. If you are really stuck, try to parse out just one field at a time. It is okay to have several parsing rules per log type, if necessary.
- Try to proceed one field at a time, if possible. Get the one field extracted correctly, and then proceed to the next one.
When you create a parsing rule, it will apply to new logs that are collected. I have waited a bit for more logs to come in, and I can see they are now parsing as expected.

Now, I need to create a second rule for the next type of log. Here is what those logs look like
<14>May 27 16:25:31 tkxr7san01.widgets.local MSWinEventLog 1 Microsoft-Windows-PrintService/Operational 5794 Mon May 27 16:25:31 2021 307 Microsoft-Windows-PrintService hfinn User Information tkxr7san01.widgets.local Printing a document Document 71, Print Document owned by hfinn on lpt-hfinn01 was printed on XEROX1001 through port XEROX1001. Size in bytes: 891342. Pages printed: 2. No user action is required. 2447841
When you create a second (or third, fourth, etc.) parsing rule for the same logs, the Custom Parsing Tool does not know about the previous rules. You will need to start any additional rules just as you did the first one.
Also, just like before, as I am creating the parsing rule, I will need to apply a filter to match these logs. The type of log is “Printing a document”, so I will use that as the filter.
Again, I will start in guided mode and define the fields I want to start parsing out — it isn’t required to start in guided mode but, sometimes, that is easier. I defined a few fields, and as you can see, the parsing is not working like I need.
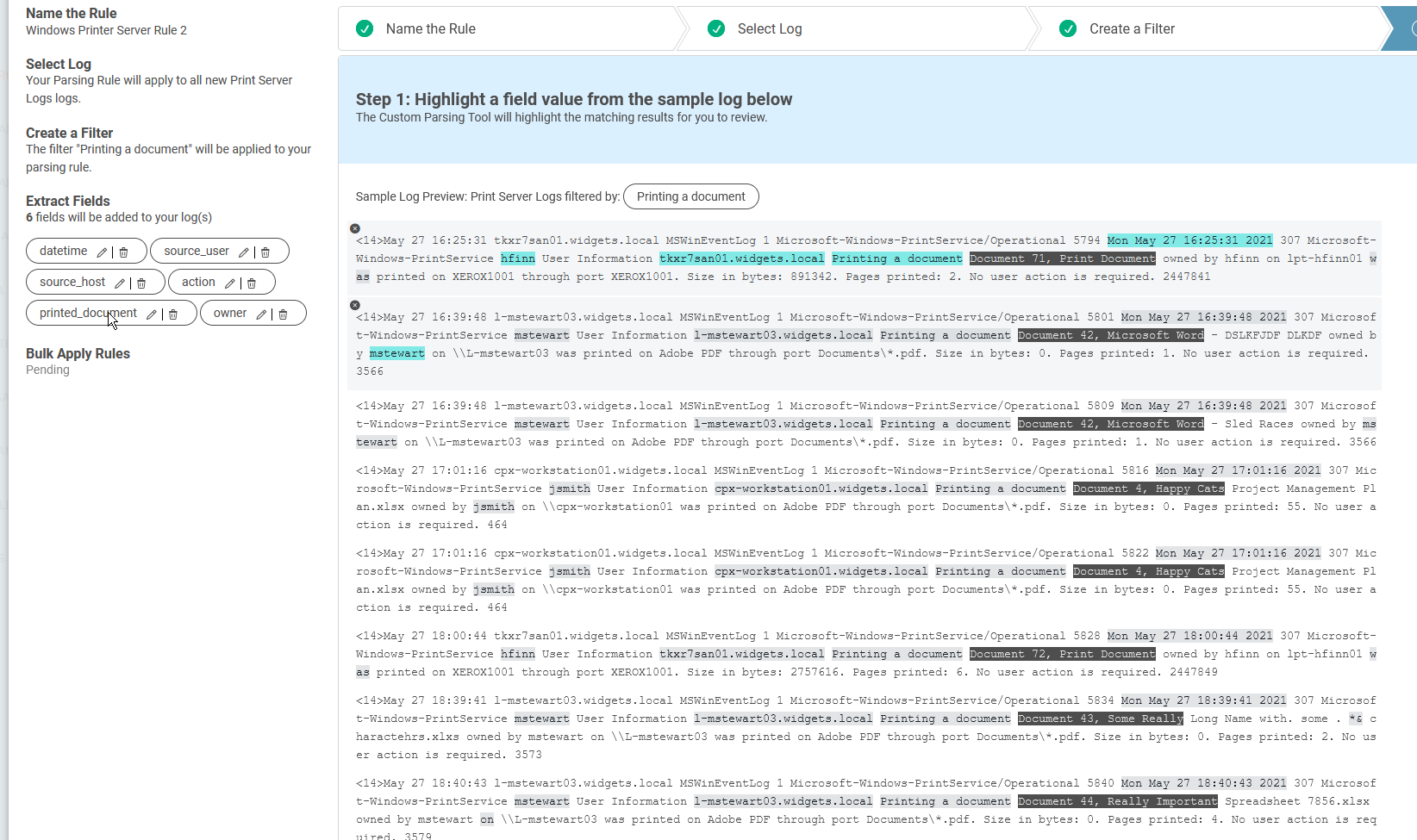
Now that I have the fields defined, I’ll switch to Regex Editor mode.
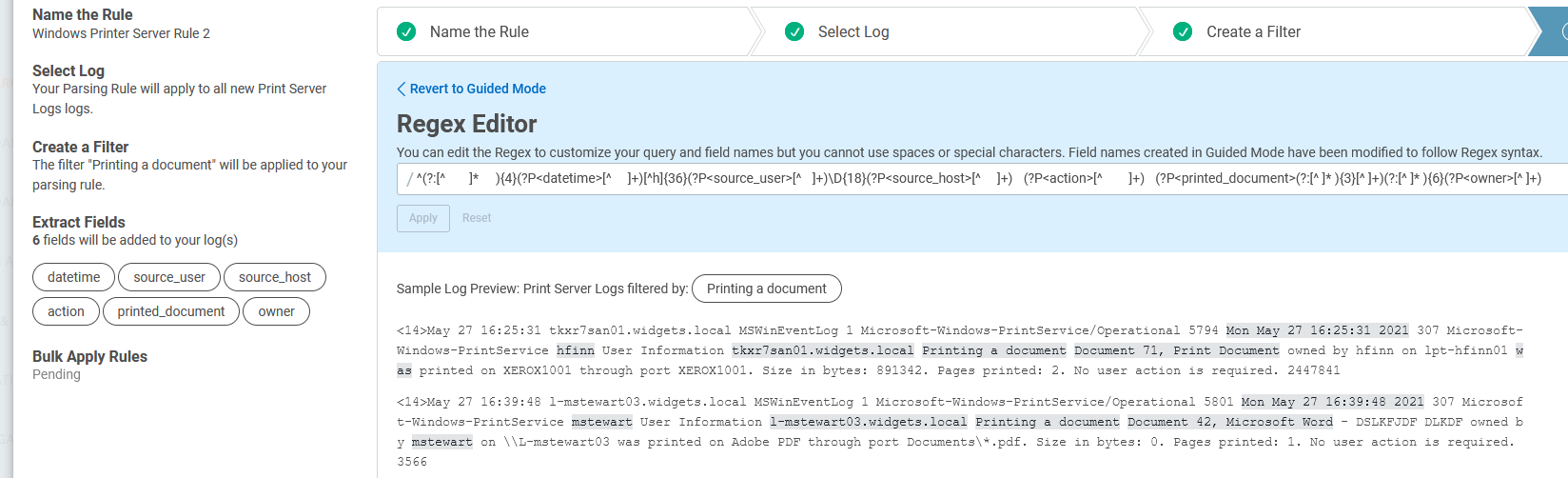
The regex that was generated in guided mode is:
^(?:[^ ]* ){4}(?P<datetime>[^ ]+)[^h]{36}(?P<source_user>[^ ]+)\D{18}(?P<source_host>[^ ]+) (?P<action>[^ ]+) (?P<printed_document>(?:[^ ]* ){3}[^ ]+)(?:[^ ]* ){6}(?P<owner>[^ ]+)
Just like before, I am going to clean this up a bit, starting with the first field and working from left to right, modifying the regex to parse out the keys like I want.
The first part of the regex, “^(?:[^ ]* ){4}(?P<datetime>[^ ]+)”, says to skip past the first four spaces and read the next part into the datetime key until a fifth space is read. This first part is fine and parsing out the field as needed, so let’s move on to the next part, “[^h]{36}(?P<source_user>[^ ]+)”.
For simplicity and functionality, I am going to swap out the way the regex is skipping over to the username, “[^h]{36}”, with “(?:[^ ]* ){3}”. This is using the same logic as the first rule: skip past three spaces to find the next value to read in.
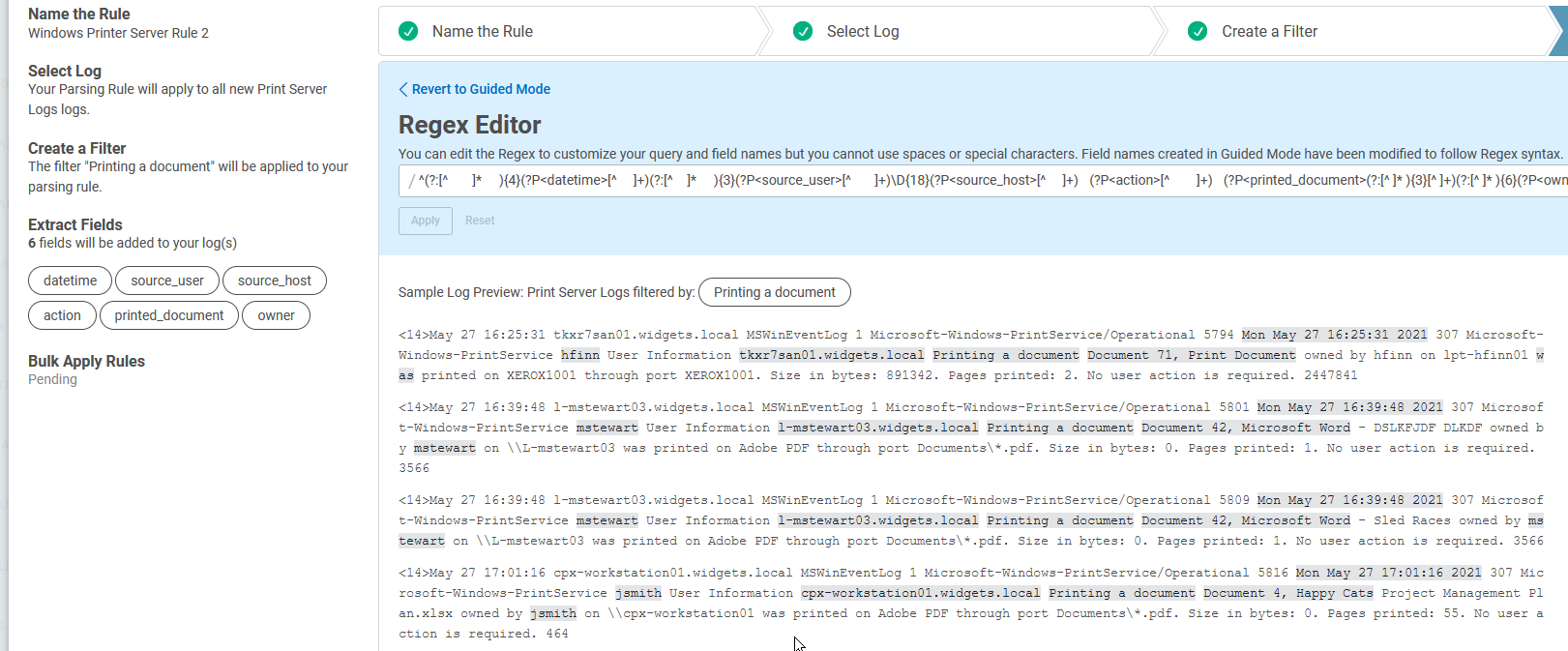
These first two fields are working, so let’s move to the next one, “source_host”. The regex for skipping over to this field and parsing it is: “\D{18}(?P<source_host>[^ ]+)”.
While this might look odd, the “\D{18}” part is how regex skips over the literal string “User Information”. We looked at “\D” previously; the “\D” means to match “any non-digit character”, and the “{18}” means “18 times”. In other words, skip forward 18 non-digit characters. This is working well, and there is no need for any tinkering.
The next field is “(?P<action>[^ ]+)”, and just like the previous one, this field is properly parsed out. If a field is properly parsed, then there is no need to make any changes.
Now, I am getting to the messiest field in the logs, which is the name of the document that was printed. You can see that the field should contain all the text between “Printing a document” and “owned by'', and it is not being correctly parsed with the auto-generated regex.
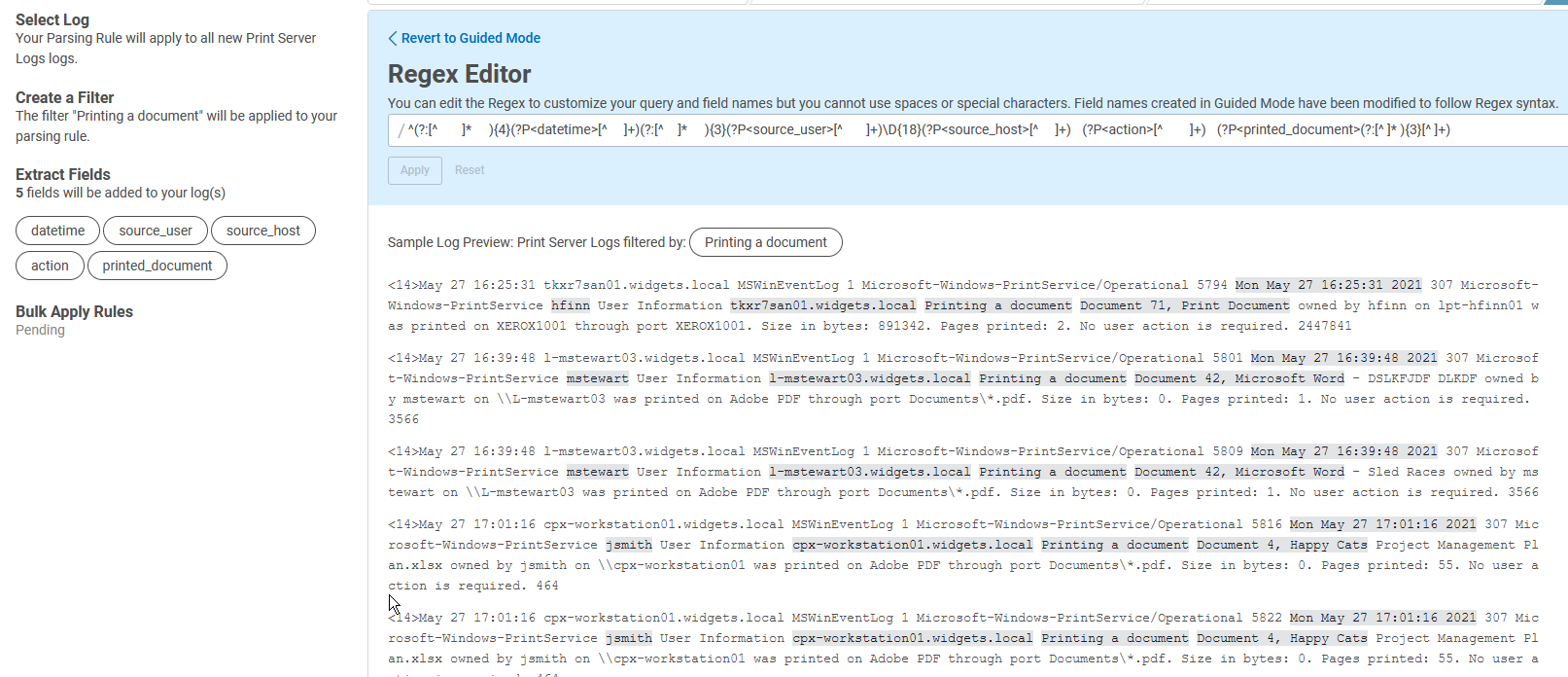
Hey, we humans are still better at some things than machines! While this field is easy for us to make out, machine-generated regex has difficulty with these types of fields.
Let’s look at the current method that regex is using. The field is parsed with “(?P<printed_document>(?:[^ ]* ){3}[^ ]+)”, which means the parser is counting spaces to try to determine the field, and that just doesn’t work here. We need to craft a regular expression that will parse everything until we get to “owned by”, no matter what it is.
The best way to do this is to create a character class that includes all the possible characters that might be in the field to be extracted. Because a document can contain any possible character, I am going to use the class “[\d\D]”, which I used previously. To say “followed by the literal string owned by”, I need to be careful and take into account the spaces.
Spaces can be a little tricky in that, sometimes, what your eyes perceive as one space are several. To be on the safe side, instead of specifying one space with “\s” you might want to use “\s+”. You could also put an actual space there. That is what the auto-generated regex has; however, I prefer to use the “\s+” notation as it makes it clear that I want to match one or more spaces.
(?P<printed_document>[\d\D]+)\s+owned\s+by\s+
Before continuing, I am checking to make sure the “printed_document” field is parsed properly.
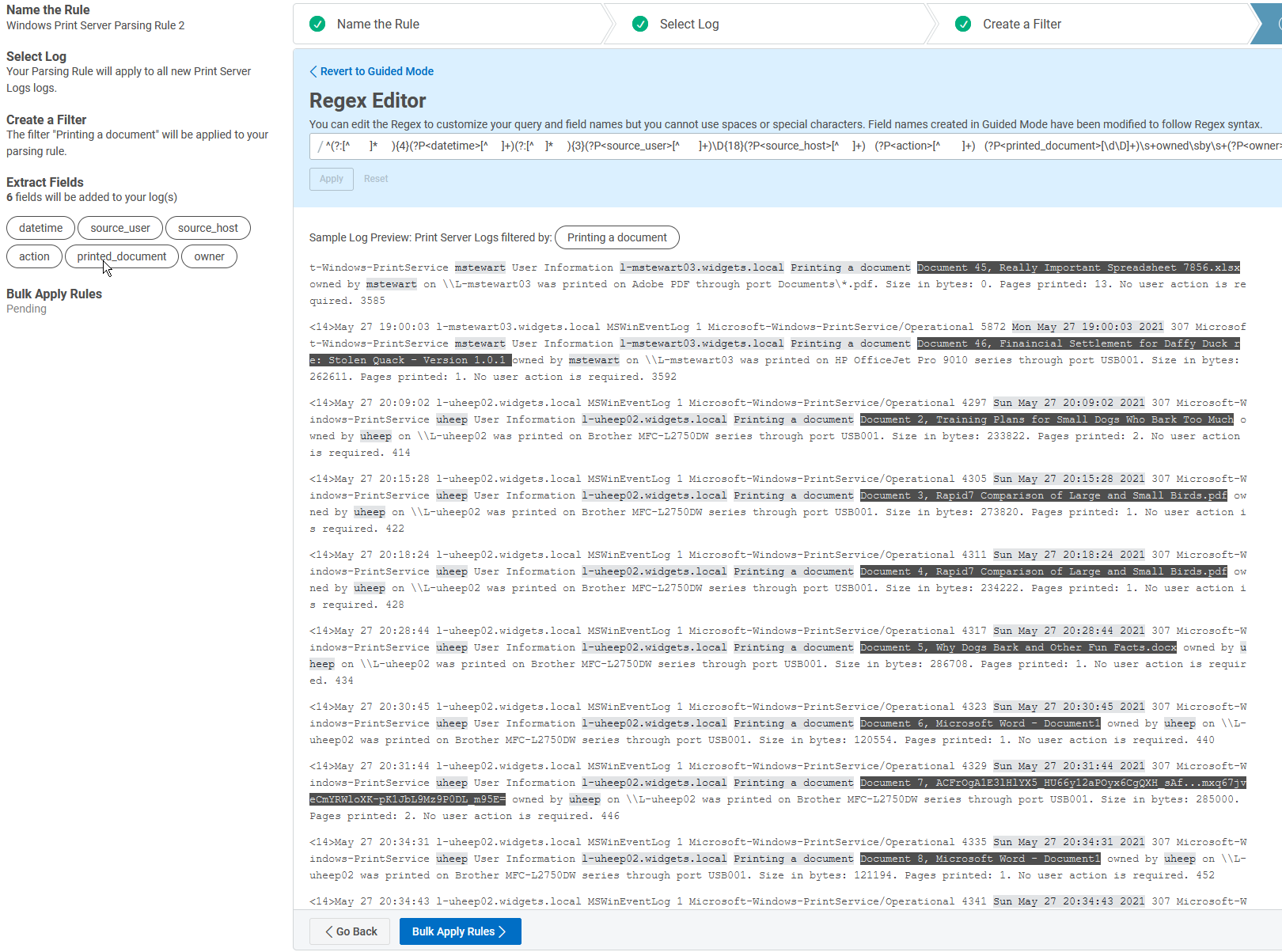
It all looks good! If it didn’t, I would fiddle with the parsing until it did. The last field owner is parsing correctly, as well
Drat! I need to extract one more field, and I forgot to define it in guided mode. That’s okay, however, because I can go ahead and add it right now. All I need to do is to create a named capture group for it.
We looked at the syntax for a named capture group earlier:
(?P<key>regex that will extract the value)
I want to collect how many pages were printed, so let’s look at our logs again. I’m working on this part of the log:
owned by mstewart on \\L-mstewart03 was printed on Adobe PDF through port Documents\*.pdf. Size in bytes: 0. Pages printed: 13.
I need to skip forward from the “owned by” value all the way over to “Pages printed”. The fields in between might have different numbers of spaces, characters, etc., which means I can’t count spaces like I did before. I can’t count the number of characters, either.
Let’s use our old friend “[\d\D]”:
(?:[\d\D]+)Pages printed:\s+(?P<pages_printed>\d+)
The tool seems happy with this, as there are no errors when I click on Apply, and the fields in the Log Preview appear to be correct.
When I apply and save this rule, I wait for a few more logs to come in to see if the parsing rule is working like I want. In Log Search, here is a parsed log line:

You might be wondering what the “\t” is all about. The “\t” is a tab or space character, and I’m not quite satisfied with my parsing rule. I didn’t spot when I saved it that there is a space being captured at the beginning of the field. If you find, after you save a rule, that it isn’t working like you want, you can either delete it and start over or just modify the existing rule.
I am going to modify my rule and fix it. Here is my final regex with the extra spaces accounted for:
^(?:[^ ]* ){4}(?P<datetime>[^ ]+)(?:[^ ]* ){3}(?P<source_user>[^ ]+)\D{18}(?P<source_host>[^ ]+) (?P<action>[^ ]+)\s+(?P<printed_document>[\d\D]+)\s+owned\s+by\s+(?P<owner>[^ ]+)(?:[\d\D]+)Pages printed:\s+(?P<pages_printed>\d+)
And that’s it! With this guide, you have now learned how to use the Custom Parsing tool in InsightIDR to break up ugly logs into usable fields.
