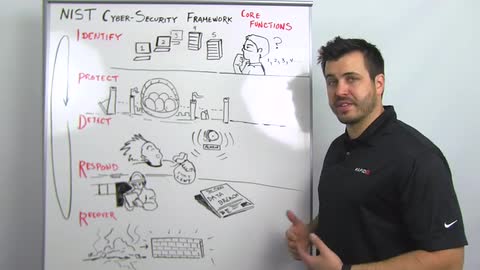
I think a couple of things about this are innovative. We're going to tear these apart in upcoming Whiteboard Wednesdays and blog posts, but I want to give a real quick overview of what this means. They break this process down into identify, protect, detect, respond, and recover.
Identification, I think laughably, is an important place to start. Some organizations deal a lot with mergers and acquisitions. You're acquiring new systems, new environments. You don't know what you're getting. I think a lot of times this is something we spend a lot of time doing inside of our own networks is scanning and discovering devices, getting an idea not just of what assets we have under management but what assets probably don't belong on our network. Finding out what all we have, verifying that we know where centers of gravity important data sets or critical assets live. The identification process should be an ongoing loop. This is called out and described fairly carefully in this framework.
Next is protect. Once you know where all your eggs are, you can move them into a basket. Then, you work on defending them. This allows you to simplify your approach to defense. It allows you to save some investment, some money, some budget on how you're protecting. You don't have to protect everything the same way. I would make the reference to Fort Knox security. Unless you're protecting gold, you may not need to protect it as aggressively.
You've identified assets. You're protecting what's important. Then, there's the detection piece. Once you've identified assets, centralized them, and started to build protection around them, then you have choke points. You have logical places to make sure you're gathering logs, setting baseline behavioral patterns, and getting an idea of what normal looks like so you can identify anomalies. You can identify things that look out of place. It simplifies what all you have to investigate.
Response is important. The illustration we have here is a fire chief going through doing a fire code inspection. Checklists are fairly important, fairly useful. We do this today with other regulatory frameworks, but they're calling out a communications plan, this notion that if and when. It's not if and when but where and how something's going to happen that you're prepared, that you have a framework. You have an approach not just to cleaning out a miscreant but also being able to go through a clean communications plan for internal, if necessary external, communications and then a process to make sure you're folding in lessons learned in the recovery process. It's not just about making sure you get back to a trusted computing platform, getting back to a known good computing state, but also folding those lessons learned building that back into your protection and detection strategies making sure you learn recover and execute better in the future.
Thanks for tuning in. We'll see you next week